SPSS K-Means
SPSS K-Means
K-Means analysis using SPSS
Mock data comprising of 504 records of hotel reviews by travellers was fed into SPSS. The data included information of travellers, their traveling periods, hotel reviews and facilities.

Clustering was performed using the K-Means module in the SPSS to identify combinations of hotel facilities preferred by travelers. It was aimed to determine whether all six facilities—Casino, Spa, Free Internet, Gym, Pool, and Tennis Court—were important to travelers, or if certain combinations of facilities held more significance.
SPSS excels in allowing users to easily analyze the results of different cluster sizes. However, the meaningfulness of each determination can vary. I ran the program with cluster sizes ranging from 2 to 7, and noticed that the results became less meaningful as the number of clusters increased. By applying Occam’s razor—the principle that the simplest solution is often the best—I decided to use the output from the three-cluster analysis, as it provided the most interpretable and practical results.
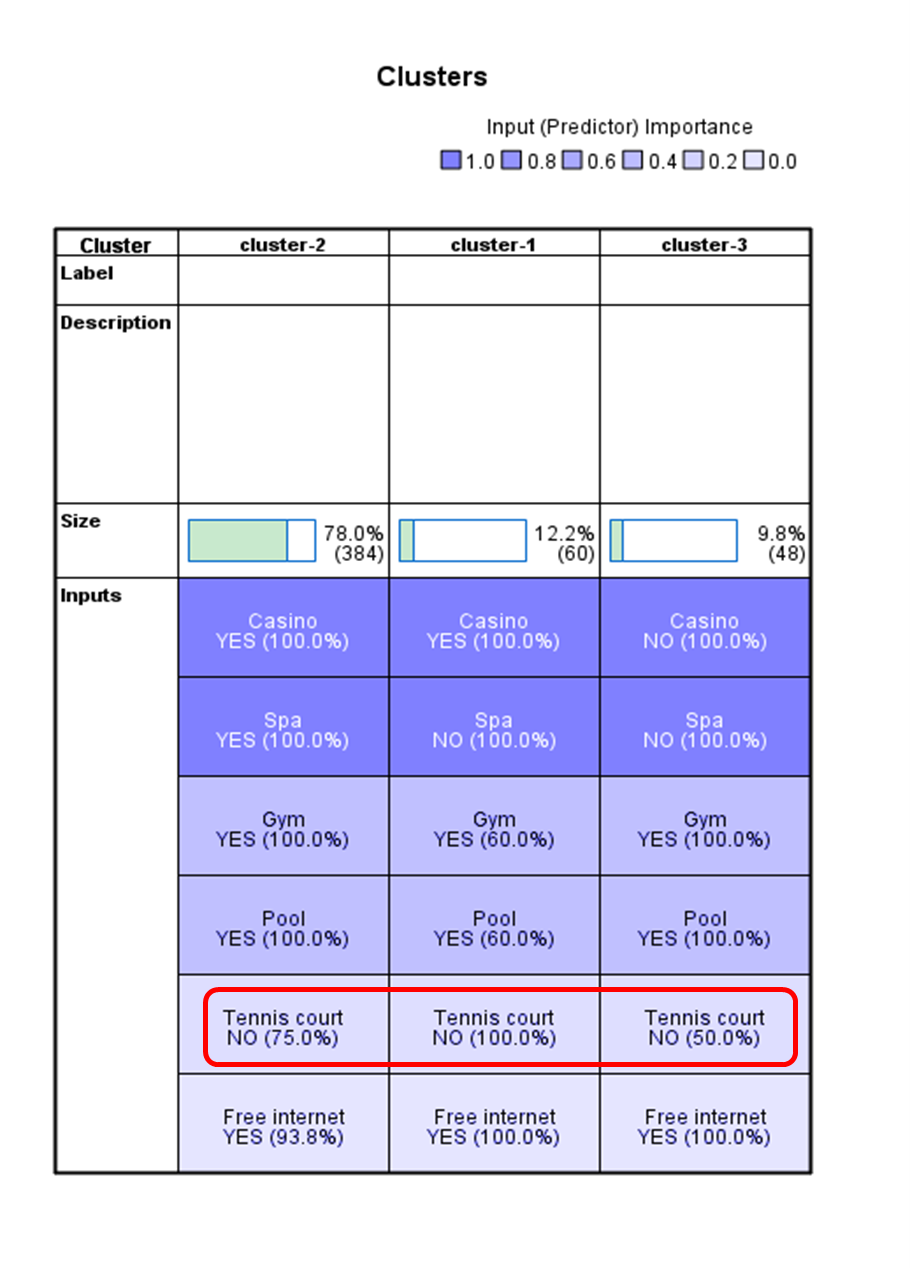
Sometimes, it is the ‘not so obvious’ insights that matter
We often focus at the obvious combinations, such as spa and casino, spa and gym, or spa and other amenities. However, a deeper look at the results revealed that most travellers did not consider a tennis court a must-have. So, how should you prioritise your business offerings with this finding?